目前微调预训练的深度模型在视觉分类领域已经成为了主流的范式。通过迁移预训练模型的语义信息到下游任务数据集,能够有效避免微调中的过拟合问题。当前主流的在预训练的范式,已由过去依赖有标注数据的有监督预训练(例如在ImageNet上的分类预训练)发展为更容易在大规模无标注数据上扩展的无监督预训练(例如掩码自编码器)。
然而,困扰微调的一大挑战是迁移学习过程中的灾难性遗忘。灾难性遗忘指的是使用较大的学习率进行微调,会使得微调后的模型与没有微调的预训练模型差异过大,导致预训练模型中的知识被遗忘。显然,这个问题可以通过设置较小的学习率来缓解。然而,这样的做法会带来另一个挑战,那就是继承预训练模型中潜在的数据偏差。值得注意的是,预训练模型是通过特定的任务在预训练数据上学习的。这意味着如果下游任务数据集的分布与预训练的数据分布差异过大,微调模型难免会从预训练数据分布中继承部分数据偏差。这一问题在缓解灾难性遗忘的情况下会格外严重,因为较小的学习率使得微调模型会更接近预训练模型。
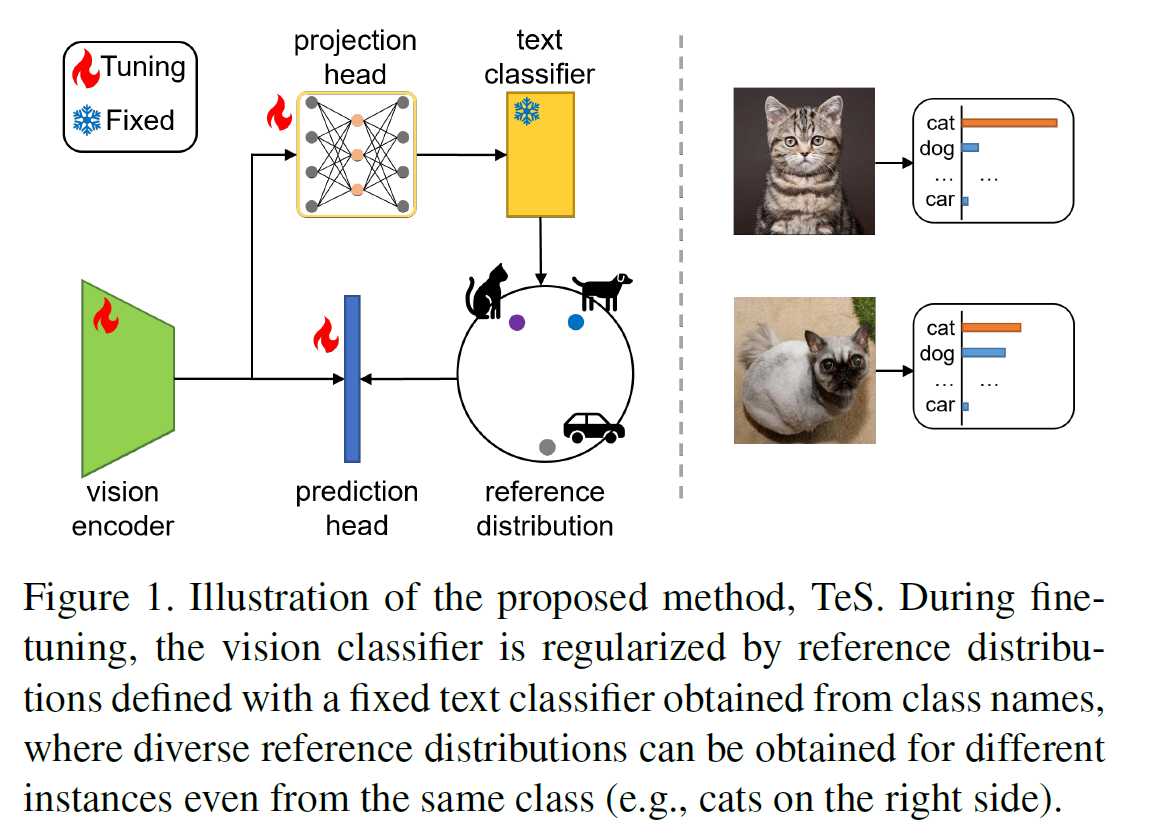
最近已由许多工作证明了另一个模态可以帮助视觉学习。例如CLIP通过两个模态的编码器和图文对预训练使得模型获得了强大的零样本能力。仅使用数据集的类别名作为文本描述,CLIP能够实现媲美有监督训练的模型性能。遗憾的是,这种架构需要成对的编码器,这意味着不适用于针对单一编码器微调的方法。在视觉微调领域,目前仍缺少一种通用性的方法能够解决数据偏差问题。
在本工作中,我们提出了一个创新性的架构TeS(Text Supervised fine-tuning),能够利用文本模态的预训练信息缓解迁移学习中数据分布偏差的问题。通过一个预训练的文本编码器,我们可以利用下游数据集的标签名获得这些类别的参考分布。我们在常规的微调中加入了对微调模型分布与参考分布差异的量化,并以降低该差异为优化目标。最终微调的优化目标包括两部分,第一部分是视觉微调损失,由标准的交叉熵损失和相较于参考分布的KL散度构成,第二部分是文本映射损失,用于实现任意一个视觉模型到参考分布的映射。