介绍
在多模态学习的发展中,出现了两个递归层次:(1)多模态关联;(2)跨模态生成。前者依赖于多模态输入,通过关联表达式计算出给定多模态输入的关联分数。典型的任务包括图像分类、图像-文本检索、目标检测等。后者是将输入从一种模态转换到其他模态,这需要一种跨模态的转换关系,以确保不同模式内的同一概念能够被准确表达。典型的任务包括图像到文本和文本到图像的生成。
目前,以CLIP和ALIGN为代表的视觉语言预训练模型(VLPMs)已经通过基于多模态关联的对比学习在第一层次上获得成功。通过4亿的海量(图像、文本)训练数据,CLIP成功地建立了视觉模态和文本模态之间的关联。受益于多样化的训练数据,CLIP对开放世界的知识有广泛的感知。在没有微调的情况下,CLIP在ImageNet的零点设置中实现了76.2%的准确率,并在具有多个领域的数据集上媲美甚至超过了微调模型。许多基于多模态关联的工作都受益于CLIP强大的零样本能力:不仅避免了监督数据的高收集成本,而且简化了部署过程。CLIP在关联层面的巨大成功引发了在生成层面的探索。然而,由于CLIP没有解码器架构和生成的预训练任务,它不能胜任基于生成的任务。
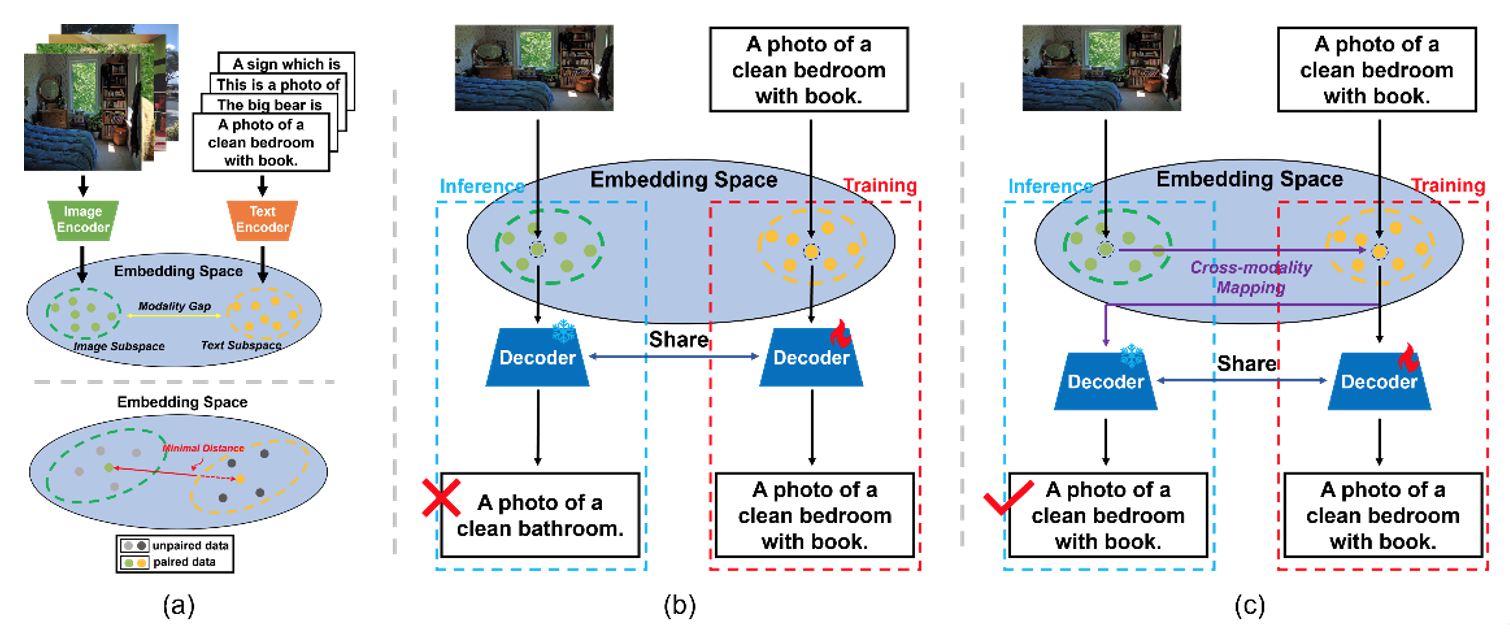
尽管如此,大规模语言模型如BERT和GPT的出现使得从CLIP的嵌入空间解码成为可能。它是在此基础上产生的基于多模态联合空间的零样本生成的想法: CLIP在嵌入空间中对图像和文本进行了足够接近的编码。然而,有工作表明,CLIP将图像和文本编码为两个独立的子空间,并且它们之间存在着明显的差距,如图(a)顶部所示。这意味着解码器只在一种模式下有效。当把解码器从一个模态转移到另一个模态时,模态鸿沟导致无法准确理解表征,如图(b)所示。
方法
为了消除模态鸿沟的影响,一个主要问题是如何建立两种模态之间的转换关系。一个自然的想法是通过大量的监督数据来模拟这种关系。然而,这需要大量的监督数据和训练资源。我们认为,这种关系可以通过CLIP的关联能力用无监督的方法建立。基于此,我们提出了K-近邻跨模态映射(Knight),一种纯文本训练的字幕方法。首先,我们从图像-文本和视频-文本数据集中收集标题作为语料库。在训练阶段,我们首先从语料库中选择字幕进行训练,并使用CLIP相似度来检索与训练字幕最相似的k-近邻字幕。然后,我们使用训练字幕的CLIP特征,通过自动回归损失来训练解码器。在推理阶段,Knight可以同时应用于图像和视频字幕。对于图像字幕,我们检索与推理图像最相似的k-nearest-neighbor字幕。对于视频字幕,我们对每个关键帧的检索结果进行平均,以实现视频的多帧输入。Knight使解码器只作用于文本子空间,从而消除了模式差距的影响,如图(c)所示。