介绍
尽管深度学习模型取得了巨大的成功,近期许多研究表明其倾向于学习训练集中的捷径线索。这种捷径线索和标签往往存在虚假相关性(即偏见),利用捷径特征进行决策的模型无法在OOD数据上进行泛化。根据在训练阶段偏见信息是否可获取可以将当前的去偏方法分为两类:有监督去偏和无监督去偏。由于在训练阶段获取偏见信息的成本较大,当前的去偏工作更多关注于更有挑战和符合现实情况的无监督去偏设置,即在没有偏见信息的情况下去偏。
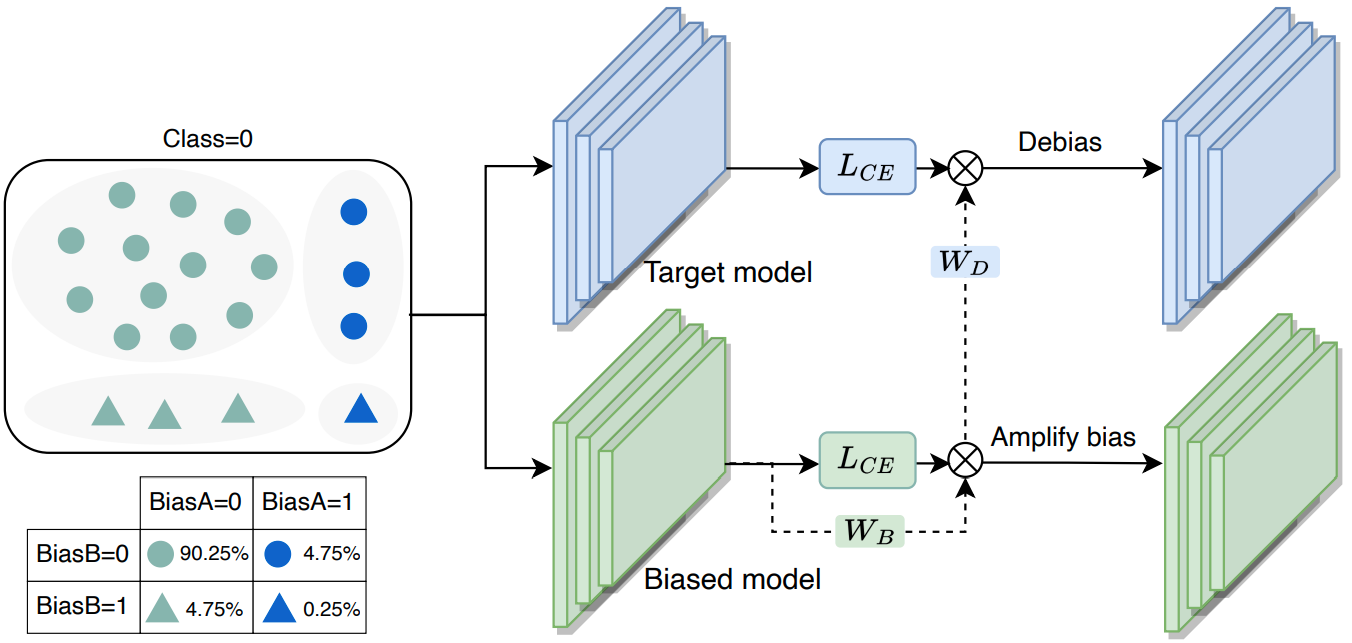
无监督去偏方法一般假设偏见特征相比于目标特征更容易被模型学习,即在训练过程中偏见特征会更早被模型捕捉(“easy-to-learn”假设)。基于这个假设,无监督去偏方法通常训练两个模型:一个是偏见模型,专门用于学习偏见特征,所以其预测结果可以当做伪偏见标签,即用于区分一个样本是偏见对齐的还是偏见冲突的(示例见图1)。另一个是目标模型,其利用偏见模型提供的伪偏见标签进行去偏。
方法
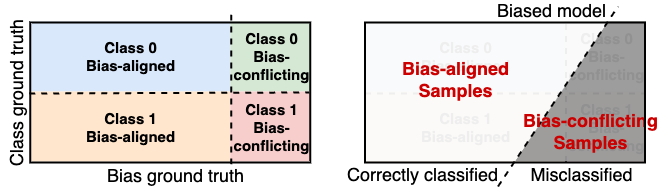
在本文中,我们提出了一个简单有效的无监督去偏方法Echos,其在回音室中训练偏见模型和目标模型。不同于现有偏见模型的训练,我们从媒体传播中的回音室现象中得到启发,在训练阶段像回音室中的信息变化一样不断地调整样本的权重,从而使有偏模型能够区分有偏差的样本和有偏差的样本。具体来说,根据“easy-to-learn”假设,我们认为在早期训练阶段,偏见模型正确分类的大部分样本是有偏对齐的,而模型错误分类的样本中只有少数是偏见对齐样本,大部分都是偏见冲突样本。基于这个分析,我们可以通过降低错误样本的权重来“隐藏”这些样本不被模型学习。而被偏见模型正确分类的剩余样本将在下一轮训练中被重新训练,就像回音室中的回音一样。最后,有偏模型将充分地偏见对齐的样本中学习,同时在偏见冲突样本上欠拟合,从而可以向目标模型提供更准确的偏向信息。偏见模型的整个训练流程如图3所示。
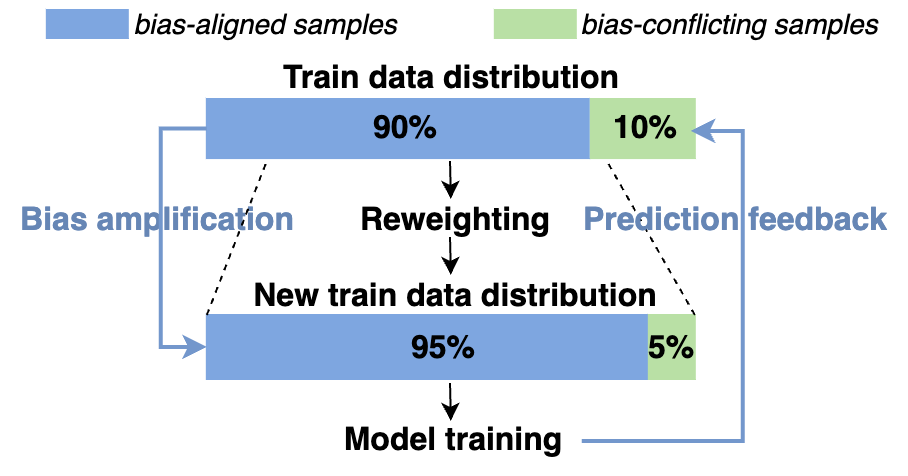
在回音室中,较低的样本权重表明它更容易被偏见模型错误分类,而较高的权重表明它更经常被偏见模型正确分类。这意味着权重较低的样本更难被偏见模型学习,因此它们对目标模型更加重要。基于这一分析,我们简单地使用偏见模型的样本权重的倒数作为目标模型的样本权重,这样目标模型就可以专注于学习偏见冲突样本,以防止学习虚假相关性。模型整体框架如图4所示: